
Get rid of mock maintenance with full fledged in-memory fakes
Last week’s post was about how hexagonal architecture results in fast, mock-free tests around your core domain. Unfortunately, that does not remove all mocks, yet it groups them in the same, less critical, zone. In last week’s code sample, this was the controller. I concluded that at least, this was easier to manage. Let’s see how.

This is the 7th post in a series about avoiding mocks. If you haven’t, you might start from the beginning.
Mock concentration
Let’s get back to the last post’s code sample. As a reminder, it’s a very basic TODO app built on Rails. I extracted the domain part, the tasks, in a core domain area. This allowed to push all mocks out of this section. A consequence though, is that all mocks gathered in the controller test. Here is the controller code :
require 'core/task'
require 'infrastructure/task_repo'
class TasksController < ApplicationController
before_action :set_task, only: [:show, :edit, :update, :destroy]
# GET /tasks
def index
@tasks = Infrastructure::TaskRepo.all
end
# GET /tasks/1
def show
end
# GET /tasks/new
def new
@task = Core::Task.new
end
# GET /tasks/1/edit
def edit
end
# POST /tasks
def create
begin
@task = Core::Task.new(task_params)
Infrastructure::TaskRepo.save(@task)
redirect_to task_url(@task.db_id), notice: 'Task was successfully created.'
rescue ArgumentError
render :new
end
end
# PATCH/PUT /tasks/1
def update
begin
@task.update(task_params)
Infrastructure::TaskRepo.save(@task)
redirect_to task_url(@task.db_id), notice: 'Task was successfully updated.'
rescue ArgumentError
render :edit
end
end
# DELETE /tasks/1
def destroy
Infrastructure::TaskRepo.delete(@task)
redirect_to tasks_url, notice: 'Task was successfully destroyed.'
end
private
def set_task
@task = Infrastructure::TaskRepo.load(params[:id])
@task.notify_when_done do |task|
TwitterClient::Client.update(task.description)
end
end
# Never trust parameters from the scary internet, only allow the white list through.
def task_params
params.permit(:description, :done)
end
end
The controller is now dealing both with the Twitter connection and the database. This is visible in the controller test :
require 'rails_helper'
RSpec.describe TasksController, type: :controller do
before :each do
allow(TwitterClient::Client).to receive(:update)
end
# ...
describe "PUT #update" do
context "with valid params" do
let(:new_attributes) {
{done: true}
}
it "updates the requested task" do
task = Task.create! valid_attributes
put :update, params: new_attributes.merge(id: task.to_param)
task.reload
expect(task).to be_done
end
it "tweets about completed tasks" do
task = Task.create! valid_attributes
expect(TwitterClient::Client).to receive(:update).with(task.description)
put :update, params: {id: task.to_param, done: true}
end
it "redirects to the task" do
task = Task.create! valid_attributes
put :update, params: valid_attributes.merge(id: task.to_param)
expect(response).to redirect_to(task_url(task.id))
end
end
# ...
end
end
We need to stub out the twitter API for most tests. We are also still using a mock to verify that the tweet is sent. Finally, as we can see from the test execution times, we are still using the database in some tests.
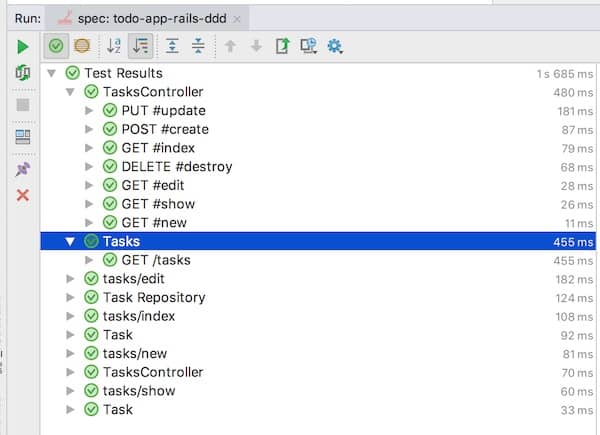
If the project grew large this would become an issue. Sadly, mocking is often the fix people jump on …
💡 Mocking is the unfortunate quick fix to slow tests.
From a mocking point of view, our current controller test can seem worse than before ! There’s something pretty effective we can do though !
In memory fakes
Instead of stubbing and mocking in every test, let’s write a full fledged in-memory fake that does the job we need. We could then install it once and for all, and forget about it !
Actually, this is nothing new. This is exactly what Rails provides out of the box with ActionMailer::Base.delivery_method = :test.
Here’s how we could do the same thing for our Twitter Client.
spec/rails_helper.rb
class FakeTwitterClient
def initialize
@tweets = []
end
attr_accessor :tweets
def update(message)
@tweets.push(message)
end
end
RSpec.configure do |config|
# ...
config.before(:each) do
stub_const("TwitterClient::Client", FakeTwitterClient.new)
end
end
spec/controllers/tasks_controller_spec.rb
it "tweets about completed tasks" do
task = Task.create! valid_attributes
put :update, params: {id: task.to_param, done: true}
expect(TwitterClient::Client.tweets).to include(task.description)
end
Simple isn’t it ?
Wait a sec …
There’s a catch though … How do we make sure that this fake is behaving the same way as the real thing ?
Let’s run the same tests on both ! We could mimic the twitter API in our fake, but that might not be a great idea. Do you remember the moto “Always wrap your 3rd parties” ? It takes all its meaning here, for 2 reasons.
The first is to make faking easier. We can build a minimal wrapper API that is just enough for our use. By keeping this interface small, we’ll make it a lot easier to fake.
The second reason is that we can write real integration tests on the 3rd party through this wrapper. They’d look like ordinary unit tests, except that they’d end up calling the real 3rd party in a sandbox. They are usually pretty slow, but as 3rd parties don’t change everyday, that’s ok. We can ensure up-front that integration will go well. As a bonus, we can be very fast to detect and contain changes to online services. (I’m looking at you Scrappers!)
Here is what it would look like for our Twitter client :
lib/infrastructure/twitter_client.rb
class FakeTwitterClient
def initialize
@tweets = []
end
attr_accessor :tweets
def tweet(message)
@tweets.push(message)
end
def search_tweets(text)
@tweets.select {|tweet| tweet.include?(text) }
end
end
class RealTwitterClient
def initialize(&block)
@client = Twitter::REST::Client.new(&block)
end
def tweet(message)
@client.update(message)
end
def search_tweets(text)
@client.search("from:test_user #{text}")
end
end
As you can see, we renamed update to tweet in the wrapper. We’d have to update the calls accordingly. Let’s look at the tests.
spec/lib/Infrastructure/twitter_client_spec.rb
require 'rails_helper'
require 'infrastructure/twitter_client'
require 'securerandom'
RSpec.shared_examples "a twitter client" do |new_client_instance|
let(:client) { new_client_instance }
it "sends tweets" do
token = SecureRandom.uuid
message = "Philippe was here #{token}"
client.tweet(message)
expect(client.search_tweets(token)).to include(message)
end
end
context FakeTwitterClient do
it_behaves_like "a twitter client", FakeTwitterClient.new
end
context RealTwitterClient, integration: true, speed: :slow do
it_behaves_like "a twitter client", (RealTwitterClient.new do |config|
config.consumer_key = "TEST_CONSUMER_KEY"
config.consumer_secret = "TEST_CONSUMER_SECRET"
config.access_token = "TEST_ACCESS_TOKEN"
config.access_token_secret = "TEST_ACCESS_SECRET"
end)
end
We had to add a search method to our interface for the sake of testing. This should remain “For testing only”. We’d also adapt the controller test to use this search_tweets method.
Let’s look at where we stand now. We’re injecting each mock only once. Tests are fast yet straightforward, almost as if they were testing the real thing. Doing so, we’ve split our system in cohesive parts and we’ve wrapped our 3rd parties. We’ve actually done a lot more than removing mocks ! Mocking really is a design smell.
💡 Merciless mock hunting will improve the design of your system !
Last word about implementation
Sometimes, this 3rd party wrapper can become pretty complicated. Try to reuse as much of it as possible between the real and the fake. For example, an ORM, like ActiveRecord for example, is a wrapper around the database. Reimplementing a fake ORM would be real challenge. We’re far better plugin it on top of SQLite instead !
References
Smart people have already spoken and written about this subject. If you want to learn more, I recommend that you have a look at Aslak Hellesøy’s Testable Architecture talk. James Shore, the author of The Art of Agile Development, also wrote a pattern language called Testing Without Mock.
Next week
This was the 7th blog post in a series about how to avoid mocks. Hopefully, I’m reaching the end ! Next week’s post should be the last in series, and deal with a few remaining points. What to do when you really need a mock ? What about mocking and legacy code ?




Leave a comment