
Incremental Software Development Strategies for Large Scale Refactoring #4 : a Pattern Language
It can sometimes be a real challenge to integrate, let alone deploy, a refactoring step by step ! Here are some patterns that make this easier.
This is the ninth post in a series about how to get sponsorship for large scale refactoring. If you haven’t, I encourage you to start from the beginning. It’s also the fourth about incremental software development strategies for large scale refactoring. My point is that it’s not possible to sell a refactoring to business people until we master those :
- How to find the time to refactor in our daily work
- How to learn to work in baby steps
- How to organize and manage this ongoing effort as a team
What about when it is not easy to split the work into incremental steps ?
Do you remember the DSL parser refactoring story in mentioned in another post ? Switching to a different parser technology incrementally sounds like an impossible mission. Even so, that’s what we did !
Here’s another story. A long time ago, I was working in a bank. We were to migrate imperative C++ financial contract models into declarative definitions in C#. We had to maintain an ugly adaptation layer. It made it possible migrate and deliver step by step. In the end, we suffered almost no bugs resulting from this transition.

Why the effort ?
Incremental refactoring implies going through Frankensteinesk intermediate situations. Situations where both the legacy and the new models exist in the software at the same time. This kind of adaptation layer costs time and energy, but doesn’t add value to the product either ! What’s the point of going through this ? Isn’t a Big-Bang change cheaper ? Here is why it is still worth doing :
- It’s safer. With incremental delivery, we confirm that what we are doing is working in production. On top of that, if something goes wrong, as we only delivered a small increment, the problem is easier to diagnose.
- It’s also safer in term of priorities. The system keeps working during all the refactoring. There’s no pressure to finish it before we can move on to the next ‘valuable’ feature. As I explained before it makes it possible to pause, and why not stop there for the moment. This can be helpful if we hit a new urgent priority.
- Finally, it creates value earlier. Instead of having to wait 2 months to get all the value, you start getting a bit of this value every week. Even refactoring create value ! They reduce the time wasted to fix bugs. They increase our productivity. Sometimes, they even improve Non Functional Requirements of the system.
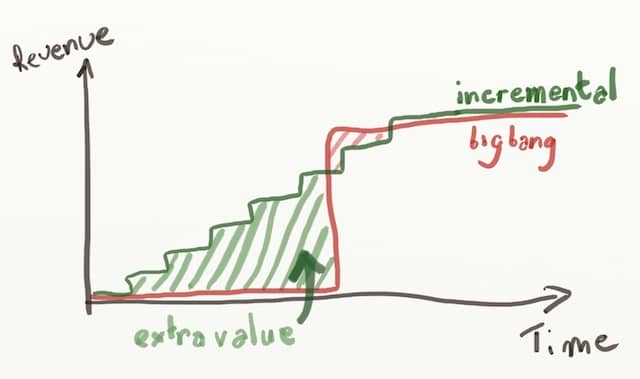
As we can see, the goal of incremental refactoring is not only to work in small steps. We also want to find a way to deliver value incrementally !
💡 Incremental refactoring is not only about baby steps, it’s also about early value delivery !
A Mini pattern language
As I said earlier, this is easier said than done. Some piece of code won’t let you refactor them step by step easily. Some will be too obscure to know where to start. Some will be just huge. Others will depend on an all encompassing third party. etc.
Here is a short pattern language to deliver large scale refactorings incrementally.
Discuss with a domain experts
Goal
We need to refactor code containing a lot of domain knowledge
Conditions
We have a domain expert available
Therefore
Have regular discussions with the domain expert to find the best modeling possible.
Consequences
- 💚 We get simpler code than by trying to replicate the twisted legacy logic
- 💚 Can save a lot of work by skipping deprecated aspects.
- 💚 Chance to get bug fixes or new features for free
- ⚠️ The system does not exactly behave as it used to, which can cause integration problems
Difficulties
It can sometimes be difficult to find a domain expert …
A lot of the presentations at the July Paris DDD Meetup were about how to find domain experts. Who actually seem to be pretty rare beasts ! Here are my notes.
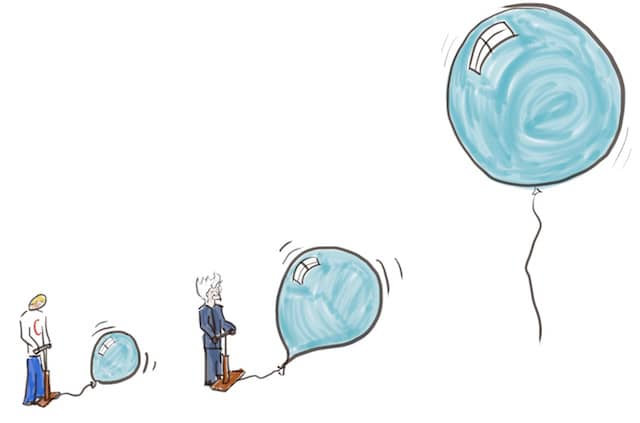
Bubble context
Goal
We want to refactor a large piece of code with no Big-Bang
Conditions
We have access to the internals of the code to refactor
Therefore
- Create a new bubble of clean code (a namespace, a package …)
- Rewrite a piece of legacy code in the bubble
- From the legacy code, delegate to the bubble
- Repeat until the legacy code is not used anymore
Consequences
- 💚 Enables a step by step continuous delivery of the new version
- 💚 It is possible to eventually transform the API of the system
- 💚 It’s easy to add new features in the bubble long before the refactoring is over
Difficulties
- Need to understand the legacy enough to find good delegation points
- Need to understand what the old small piece of code was doing to re-write it. A domain expert might be mandatory.
Strangler
The bubble context grows from the inside, but the strangler starts from the outside.
Goal
We want to refactor a large piece of code with no Big-Bang
Conditions
We can keep the same interface (API) for the legacy and the refactored versions
Therefore
- Wrap the existing code
- Re-implement calls in the wrapper
- Delegate the rest to the legacy
- Repeat until you support all the interface
- Remove the legacy code
Consequences
- 💚 Enables a step by step continuous delivery of the new version
- ⚠️ Maintenance of the wrapper and both versions of the code during all the refactoring
Difficulties
- Interaction between the legacy and the refactored version is not always as simple. For example when the wrapped code is stateful
- The granularity of the steps is the (method) calls to the interface. They need to be small enough for the whole process to be incremental
Remember my story about how we switched our DSL parser to ANTLR ? We used a Strangler to do this.

Feature toggles
Sometimes, we just don’t find a way to deliver a refactoring to users step by step. I’ve seen situations where all incremental paths implied a temporary impact on NFRs. Ex : Keeping both versions of the code implied an increase in resource consumption.
Goal
Incrementally build a refactoring that we cannot deliver piece by piece to all our users.
Conditions
When we cannot find a way to incrementally deliver our refactoring to bulk of our users
Therefore
From the code, dynamically switch to the different versions depending on runtime configuration. This way, we let most users stick to the legacy version. Yet, we can build, test, integrate and deploy the new version to beta testers.
Consequences
- 💚 We can build, integrate and test our refactored code in baby steps
- 💚 We can beta and A/B test our refactored code
- ⚠️ We need to maintain and evolve both versions of the code for a long time
- ⚠️ We need to maintain the switches in the code
- ⚠️ We only deploy to beta testers, and don’t get as much early value
- ⚠️ Duplicate the Continuous Delivery pipeline to test different feature toggle sets
Difficulties
Maintaining feature toggles is a mess. Thus, we need to
- As much as possible, prepare the code to reduce the number of switches. Ref : Branch by abstraction
- Hunt down the number of active feature toggles at any given time
- Reduce the scope of toggles. Where possible, we should push things out of the toggle into stranglers or bubbles.
Feature toggles are an alternate to branches. Even if toggles are painful to use, branches are worse ! I’m not going to go over branches. If you want to see why we should not use branches, check this talk.
💡 Feature toggles are painful, but branches are worse !
Final word
I’m done writing about Incremental Software Development Strategies for Large Scale Refactoring. This is only what I currently know about this very important topic. There’s one last thing we need to do to be successful at it. We all need to keep an eye on new ideas from the community, and to share this with our teams as much as possible.
This was the ninth post in a series about how to get sponsorship for large scale refactoring. If you haven’t start by the beginning ! In next post, I’ll start to go over how to present a refactoring in financial terms to business people.




Leave a comment