
The Similarities between Machine Learning and DDD
We discovered that DDD concepts like Event Storming, Bounded Contexts, Ubiquitous Language, Entities and Values are useful in machine learning projects.
Story of Ismail’s internship
A few months ago, had the chance to welcome Ismail as a Machine Learning intern. He worked on finding end-to-end tests that are most likely to fail given a commit. (The results were encouraging, you can read the full story in Why Machine Learning in Software Engineering)
Even if I had already played a bit with machine learning, I’m still a newbie on the matter. As I watched Ismail work, connections between DDD (Domain Driven Design) and machine learning became obvious.
Flow of Machine Learning
Before I dig into the similarities with DDD, let me illustrate the flow of machine learning.
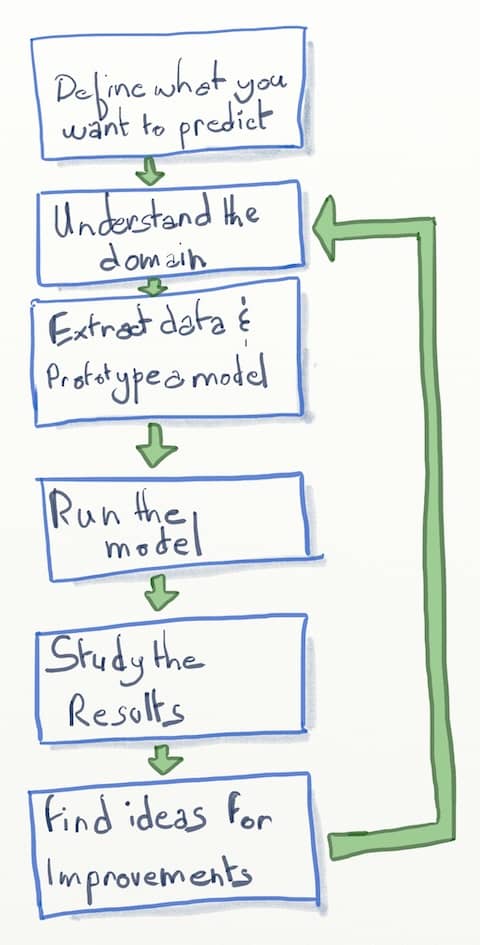
Similarities with DDD
From the schema above, we can see that once we have decided on our goal, the next step is to understand the domain. But any further improvement also starts by digging deeper into the domain… Exactly what DDD advocates to build software systems.
💡 Like DDD, Machine Learning relies on understanding the domain.
Here are selection fo DDD concepts that should be useful to machine learning.
Ubiquitous Language
The ubiquitous language is a dictionary of all the key concepts in the domain. It should improve communication between the data scientists and the domain experts. It should become easier for the data scientist to understand what the domain expert says. In return, it should be easier for the later to understand and give feedback about the models.
Bounded Contexts
Large domains are too big to be manageable. It’s a good practice to identify sub-domains that we call bounded contexts.
DDD taught us that factorizing code between bounded context can be dangerous. Here is an example. An order in the shipping context will not share much with the same order in the shopping cart context. Handling both of these in the same code creates maintenance problems.

Data Science involves some code too, especially some data extraction code. Following the DDD principles, we should not try to factorize data extraction code that target different contexts… even if they start from the same source!
The main benefit is to make the extraction code easier to evolve and refactor.
Entities and Values
A key phase of machine learning is feature engineering. This is modeling the data on which the model will run.
DDD suggests modeling data within a bounded context using Entities and Values that map the underlying sub-domain. The code gains independence from any other concern, in particular technical infrastructure. As a result, it should be more stable and easier to evolve over time.
Suppose we model features like we would model Entities and Values. We can expect features to be more stable and easier to evolve over time as well. In particular, it should be easier to completely substitute the data source for a new one.
Start with Event Storming!

Next time I start something similar, I’ll start by an Event Storming. It’s a collaborative and exploratory design workshop that emerged from the DDD community.
💡 I’ll start my next machine learning project by an Event Storming workshop.
It’s great at creating shared understanding on the domain in record time. This should get data scientists started in 1 or 2 days instead of weeks. A better start means a more sustainable pace throughout all the project.
With this shared understanding, Event Storming helps to build the Ubiquitous Language.
Finally, we can use Event Storming to identify bounded contexts. Within bounded contexts, it should be easy to model features as entities.
Running an Event Storming workshop is no rocket science. I wrote a series of blog post where I explain how to use Event Storming to identify the above artifacts.
Open question
In our case, we had to extract the data from systems that had not been built with DDD in mind. This resulted in very involved extraction code.
In contrast, the data stored by systems built with DDD in mind is more aligned with the domain. Would it be simpler to do machine learning on such systems?




Leave a comment