
Why Machine Learning in Software Engineering #2: An Experiment
A Machine Learning in Software Engineering intern identified critical tests to run. He also confirmed the open-closed principle, modular code, and small-commits!

This is part 2 of a 3 posts story about how we tried to apply machine learning to software engineering. In the previous post, I explained how data science could help us to make better decisions. If you haven’t, start reading from the beginning.
With all the technical coaching going on, I am already quite busy at work. I cannot dive into machine learning for software engineering myself. Fortunately, I found an intern to explore the topic.
Ismail’s internship
That’s how I had the chance to meet and welcome Ismail for 6 months. We had many topics to work on but here is the one we selected:
Given a commit and a list of slow-running end-to-end tests, which tests are most likely to fail?
Developers and testers used to pick the tests to run from experience. Automating this looked promising because:
- Murex has already industrialized its QA, so we had log-data to rely on.
- It could save developers from a lot of waiting-for-tests time.
The internship was not straightforward and Ismail had to go through many hoops. Still, it generated very interesting results.

Main outcome
Ismail succeeded in finding a subset of tests that are most likely to fail. The model is not accurate enough to avoid running the entire test harness though. 😞
Still, it is useful in different ways:
- It can generate a fail-fast test-suite to run first. This can find errors earlier, or increase the confidence about a commit
- It can also compute a quality-score on a commit in seconds, even before running any test
As of today, people in the QA department still need to see how to use this prototype.
Secondary findings
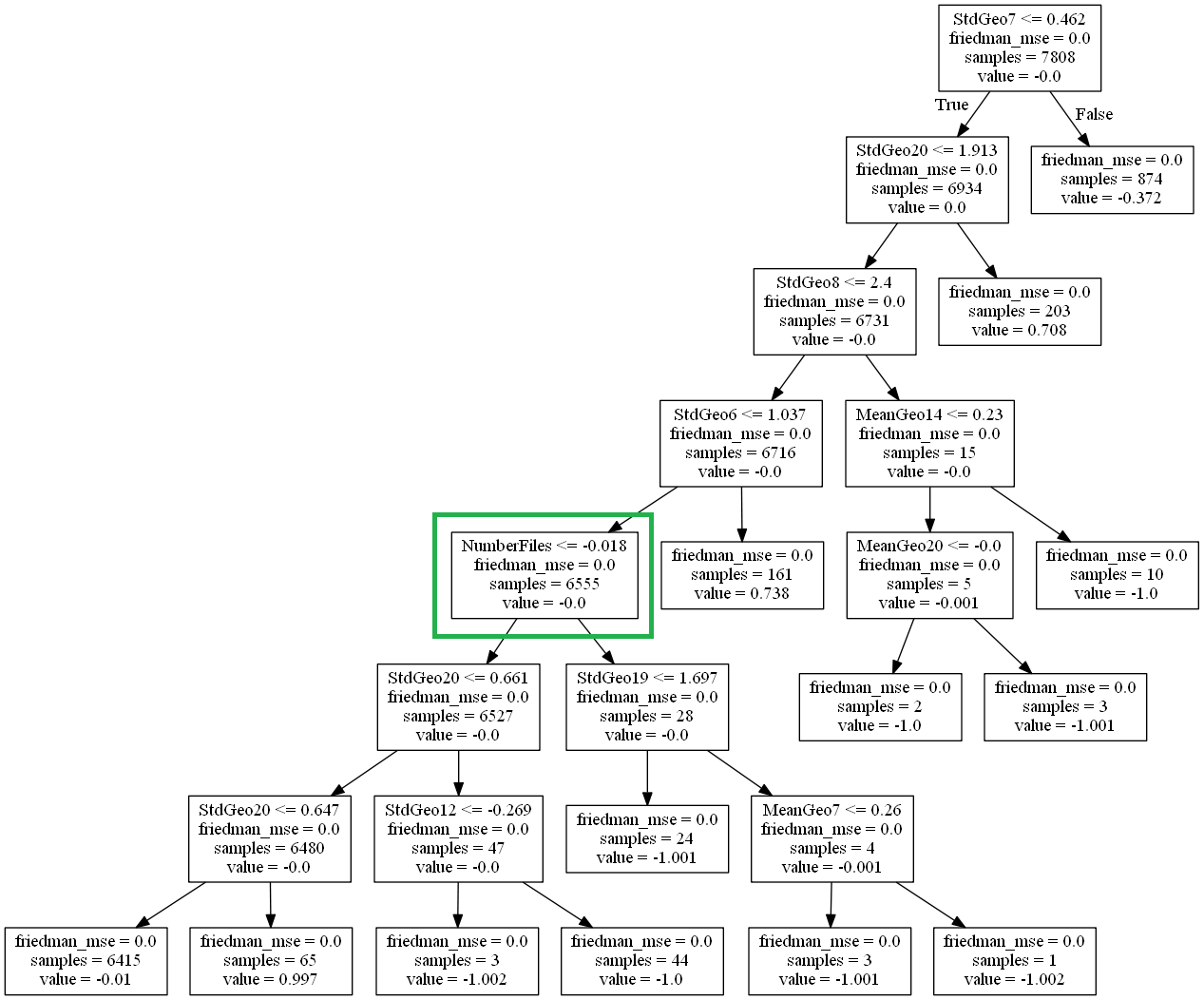
That was not all though. Ismail used the Gradient Boosting algorithm to train his models. Gradient Boosting is interpretable. A machine-learning algorithm is interpretable if it can explain its decisions. As Gradient Boosting relies on decision-trees, it’s easy to understand its conclusion.
That’s how we confirmed that software engineering best practices apply to our codebase!
Modular Code
The model relied on the position of files in the codebase. The model computes the average and standard-deviation of the positions of the committed files.
The decision-trees showed something surprising:
- The average position only had a small impact on the test result!
- Unlike the standard-deviation, which was everywhere in the decision-tree!
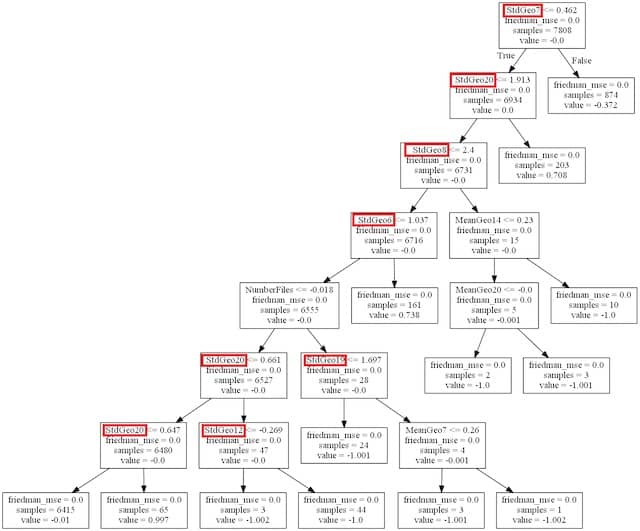
If a codebase is modular, it means that we can add new features with small and local changes. This will reduce a commit’s standard-deviation of positions. Which makes the commit more likely to pass the tests.
This confirmed that, in our codebase, modular code is easier to evolve.
Small commits
Ismail discovered that the number of files in a commit correlates with more test failures. In short, the smaller the commit, the safer.
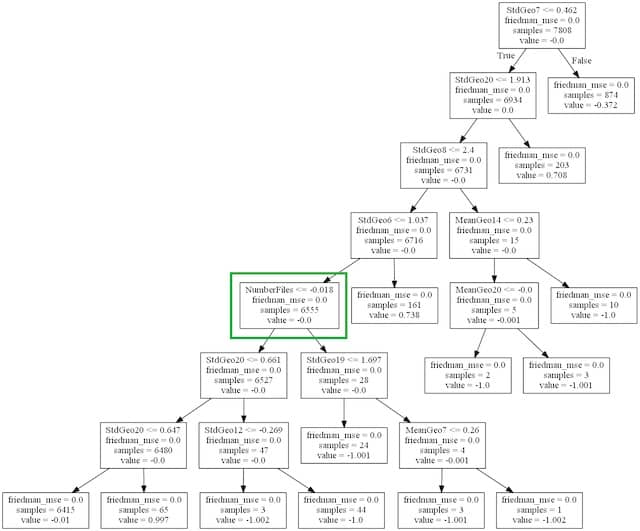
Nothing new here, but a statistical proof that this applies to a specific codebase has value. Next time a grumpy programmer tells us something like:
Small commits are fine in theory, but it does not work like that here!
We’ll have an extra argument in our pocket to get the point!
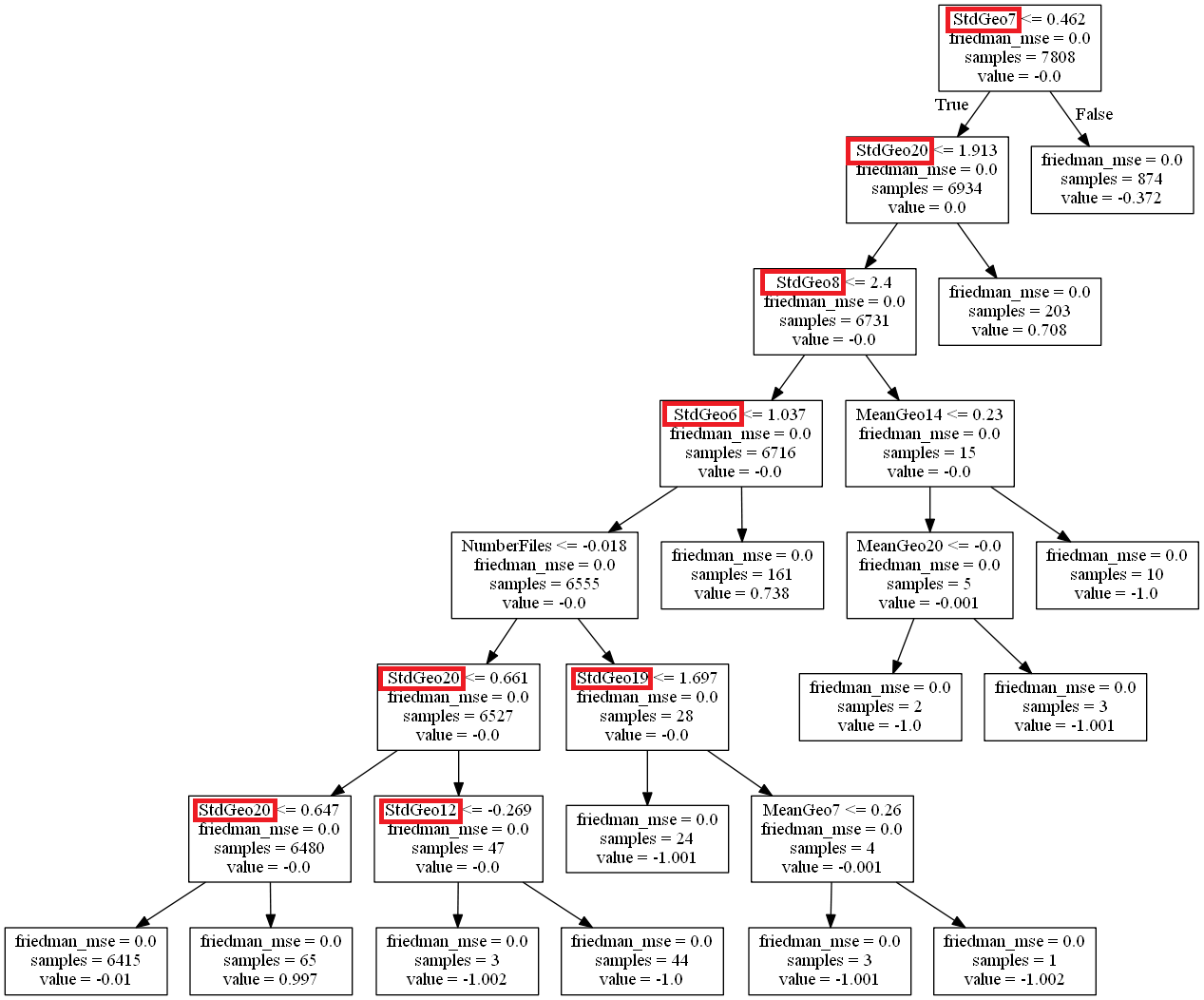
Open-Closed principle
Ismail also took into account the revisions of files in a commit. He found that the higher the standard-deviation of file revisions, the more tests fail.
When code follows the open-closed principle, new features don’t impact the old code. This means that a commit’s standard-deviation of revisions will be small. Which, again, makes the commit more likely to pass the tests.
It’s also a case for splitting new features and refactoring in different commits:
- Refactor the old code to make the change easy
- Add the feature with new code only
Again this confirms a known best practice.
To be continued
This was part 2 of a 3 posts story about how we tried to apply machine learning to software engineering. In the next post, I’ll go over different opportunities for Machine Learning in Software Engineering.
PS
Ismail and I gave a talk at Agile France 2019 and a BBL talk at leboncoin.fr. The slides are online.




{kind=link}
{kind=link}
Leave a comment