
Incremental Software Development Strategies for Large Scale Refactoring #3 : Self-Organize !
My previous posts where about how to find and use small time slots for large scale refactorings. Refactoring step by step is a series of slack slots, sub tasks of features and boy scout rule increments. Unfortunately, keeping track of all these is a challenge of its own. Here are some self-organization best practices for that.
Here is a little story of what can go bad. I used to work in a team which had a high ‘refactoring culture’. Everyone in the team wanted to apply the kind of practices I mentioned in my previous posts. To make things more tricky, we were working from 2 cities. We had introduced slack time and developers would tackle refactoring at the end of every iteration.
Unfortunately, we did not particularly organize or collaborate on slack time. As a result, we soon ran into conflicts. People wanted to refactor the same code, but in different ways! After a while we also had too many large-scale refactorings going on at the same time. This slowed down progress, increased the bus factor and the failure rate. Worst of all, it made it difficult to refocus on a newly discovered but urgent refactoring.
With a bit of self-organization though, we got things to work. Let’s see how we managed it.
This is the eighth post in a series about how to get sponsorship for large scale refactoring. If you haven’t, I encourage you to start from the beginning.
Self organize with a Design Vision
To succeed at anything, we need to know where we are going. It’s the same for large scale refactorings. We don’t need to have all the details of what we want to build. We do need a good enough draft to avoid going in the wrong direction though. That’s even more true when we work as a team. Without a shared design vision, people will refactor in conflicting directions.
It’s very important to share the vision with all the team. We can stick high level UML sketches on the walls for example. As Kent Beck suggests, we can also use metaphores to communicate the design. In this talk, Nat Pryce explains that it’s a great way start, but that we will have to drop the metaphore later.
The idea is not to waste time in a Big Design Up Front. We just want to draft a vision :
- We can run a Design level Event Storming. (Update: I wrote a full series about how to run your own)
- We can grab a copy of Gamestorming and run any another kind of collaborative design game
- Or a few team members could work on something the way they prefer
Whatever the technique we start with, we’ll be able to refine and evolve the vision down the road.
Self organize with Mikado Graphs
Remember the ‘Mikado Method’ from my previous post ? It’s a technique to code and deploy large scale refactorings in baby steps. If you had a look at the reference links, you might have seen mentions of a ‘Mikado Graph’. Here is what it looks like :
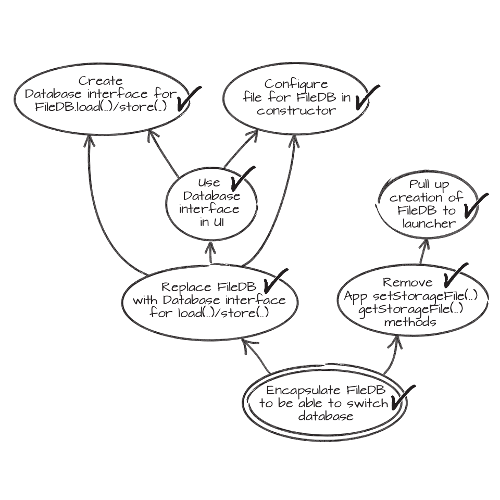
As the number of refactoring steps grows, it becomes tricky to keep track of them all. A simple way is to draw them as nodes in a graph, and tackle the work from the leaves. If you are interested, check these posts about the Mikado Method. In my previous team, we became fans of the Mikado Method. We even built a tool to generate mikado graph from JIRA (our ticket management system) dependencies! Using colors, we could track where we stood in the refactoring.
A key benefit of mikado graphs is that we can stick them on the wall. This shows to all the team where we stand in a refactoring. This way, team members can collaborate during their slack. It can also make the boy scout rule more effective. When a developer touches a file that appears in the graph, he or she can move it further in the good direction.
💡 A key benefit of mikado graphs is that we can stick them on the wall for everyone to know where we stand in a refactoring.
Self organize with Metrics
I mentioned coding conventions and a clear Definition of Done in a previous post. Having code quality constraints is the compass of constant merciless refactoring. To make this actionable and real, we should take the time to setup an automatic metrics system. For example :

- Doc Norton suggests to track maintainability, coverage, complexity and coupling over time.
- The A2DAM model suggests using specific rules to create Definition of Done constraints
Putting this in place will help everyone in the team to know if she or he should do more or less refactoring. The first benefit is that it prevents under and over engineering on new code. The second benefit is progress validation through metrics changes as we refactor.
Self organize with a bit of Planning
Granted, planning is not the most fun part of our job. It can save us a ton of work though. Joe Wright explains how they doubled their productivity by spending more time planning. If we want to make a good job of incremental refactoring, we’ll need to spend enough time preparing it. Important questions are :
- What are the most important refactorings to work on ?
- How many refactorings should we tackle at the same time ?
- Are we making good progress on our refactorings ?
- Why is this refactoring not yielding any visible results through our metrics system ?
- Are there any news that should change our plans ?
- Are we doing enough refactoring to keep things under control ?
- What are the next steps in these refactorings ?
- etc
I’m not talking about a big 6 month planning but rather regular short planning sessions. In Scrum this kind of planning happens every sprint. To make plannings more visual, engaging and fun, we might us something like Story Mapping. (I guess I should blog about this someday.)
💡 Keeping a Work In Progress limit on refactorings is essential.
Self organize through Time-Boxing
One last advice before I’m done. We must be very careful to time-box our work on refactoring increments. It’s all too easy, to get caught up in a refactoring during the slack at the end of the iteration. If we let the refactoring spill on features we risk loosing the business people’s trust.
Here again, using extra small baby steps helps to pause the refactoring. Another way is to do Kanban style slack. Replace end of sprint slack by a fixed number of people slacking all the time. But I’ll come back to this in more details in a future post.
Next post
Using this set of practices my team was able to deliver large scale refactorings in small steps.
That said, some refactorings remain very difficult to technically deliver incrementally. Fortunately, people have come up with patterns like the Strangler and the Bubble Context to cope with this. That’s what I’ll go over in the next post.
This was the eighth post in a series about how to get sponsorship for large scale refactoring.
In the previous post, I’ve been through why it’s so difficult to get sponsorship for a refactoring. Why a badass developer attitude is important? How to deliver refactorings steps by steps?
If you haven’t start by the beginning !




Leave a comment